

當企業開始把 AI Agent 放進日常工作流,模型選擇就不只是技術設定,而會影響任務品質、執行效率與使用成本。對行銷團隊來說,ChatGPT、Gemini、Claude 等模型各有不同能力取向,實際選擇時,應該回到任務類型、輸出要求、執行頻率與成本配置來評估與判斷。
這篇文章將從一般行銷人的使用情境出發,整理 AI Agent 模型選擇的幾個大方向,包括:哪些任務適合使用低倍率模型、哪些任務需要更高階的推理能力,以及如何在同一條工作流中安排不同模型角色。
以下也會以 Instag 系統目前支援的 OpenAI、Gemini、Claude 模型為例,說明不同模型等級與點數倍率,幫助使用者在建立 AI Agent 工作流時,更清楚地平衡品質、速度與點數成本。
本文段落:
- 模型沒有絕對的好壞,只有適不適合
- 模型選擇可以從 3 個問題開始
- OpenAI GPT 系列怎麼選
- Google Gemini 系列怎麼選
- Anthropic Claude 系列怎麼選
- 如果還是不知道怎麼選?先記這張圖
模型沒有絕對的好壞,只有適不適合
每個 AI 模型都是為了不同情境優化的,以「市場資訊整理」為例,一個工作流可能包含:
- 搜尋或讀取指定資料
- 摘要內容重點
- 判斷哪些資訊與品牌相關
- 整理成內部報告
- 延伸成社群貼文
- 寄送給團隊審核
這些步驟需要的能力不同,而同一個任務,用不同模型跑出來的結果可能差很多;同一個模型,換一個任務又可能表現普通,而影響結果的變數包括:
- 任務類型:客服回覆、長文撰寫、資料分析,各有擅長的模型
- 資料與知識庫品質:你給的背景資料越精準,模型發揮空間越大
- Prompt 寫法:同樣的模型,Prompt 寫得好不好,輸出差距可以很大
- 輸出格式需求:要 JSON、要條列、要純文字,模型的指令遵循能力不同
- 點數成本:高階模型可能貴上數十倍,用量大時差距非常顯著
因此,AI Agent 支援多種模型,可以讓使用者依照每個任務節點的需求,安排合適的模型。這樣可以讓工作流同時兼顧輸出品質、執行速度與點數成本。
模型選擇可以從 3 個問題開始
在選擇模型之前,可以先盤點這 3 個問題
1. 這個任務的複雜度高嗎?
如果任務只是摘要、分類、格式整理,通常可以從低倍率模型開始測試。
如果任務需要多步驟判斷、跨資料整合、策略建議,則可以考慮使用較高階模型。
2. 這個任務會大量重複執行嗎?
每日監測、批次分類、定期摘要這類任務,執行頻率較高,長期點數消耗會累積。這類任務適合先測試低倍率模型,確認輸出可用後,再固定到工作流中。
如果任務頻率低、價值高,例如:重要客戶提案、年度策略建議、重大活動規劃,則可以投入較高倍率模型。
3. 這個輸出會直接影響對外溝通或決策嗎?
如果輸出只是內部初步整理,例如:資料摘要、留言分類、關鍵字初篩,可以先使用較低倍率模型測試,優先控制執行速度與點數消耗。
如果輸出會進入客戶簡報、主管報告、品牌對外溝通,則建議使用品質較穩定的模型,並搭配人工審核。
延伸閱讀:人工審核 Human-in-the-loop 的重要性
以下整理任務類型,所對應的常見情境以及建議模型的方向,可以幫助行銷團隊建立初步選擇邏輯。實際使用時,仍建議先用同一組任務試跑不同模型,觀察輸出品質、速度與點數消耗,再決定固定使用哪一個模型。
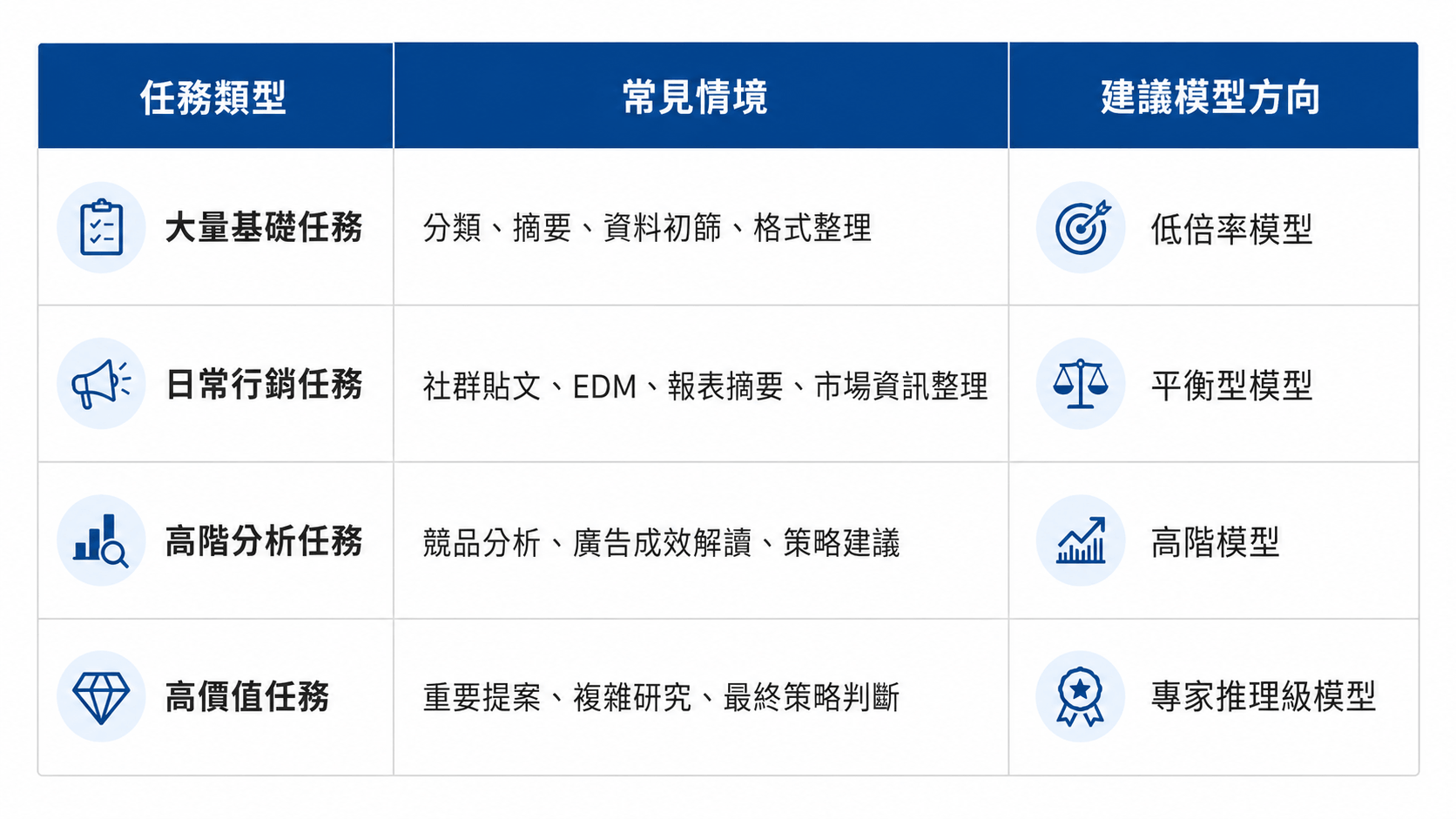
圖一、模型選擇建議
OpenAI GPT 系列怎麼選
🔴 專家推理級
gpt-5.4-pro(50.9 倍)/ gpt-5.4(4.25 倍)/ gpt-5.2 & gpt-5.2-chat-latest(3.85 倍)
這一層適合用在需要高度理解、推理與內容品質的行銷任務,例如:多份資料整合、策略建議、重要提案或品牌對外溝通。
其中,gpt-5.4-pro 點數倍率最高,適合放在錯誤成本高、品質要求高的關鍵節點,例如品牌策略分析、危機溝通建議或高價值客戶簡報。
gpt-5.4 則可作為高階任務的旗艦選擇,適合處理行銷策略推導、長文架構、跨資料源摘要與高品質文案優化。
gpt-5.2/gpt-5.2-chat-latest 可用於已驗證過、需要穩定輸出的工作流。
適合任務:
- 行銷策略分析與競品洞察
- 深度文章、品牌觀點文、提案內容
- 多份報表、新聞、輿情或會員資料整合
- B2B 銷售話術、客戶簡報、品牌危機應對
- AI Agent 工作流中的最終判斷與品質檢查
使用建議:
若只是大量分類、摘要或格式整理,可以先用低倍率模型完成前處理;專家推理級模型建議保留給需要深度判斷與高品質輸出的任務。
🟠 進階旗艦級
gpt-5.1、gpt-5(2.3 倍)/gpt-5.4-mini(1.1 倍)
這一層適合多數日常行銷工作流,能在內容品質、執行效率與點數成本之間取得良好平衡。相較專家推理級模型,進階旗艦級更適合用於高頻率、日常型任務,例如:社群內容產出、報表摘要、客服回覆草稿與一般行銷建議。
其中,gpt-5.1/gpt-5 適合需要穩定品質的日常任務,例如:文章改寫、行銷活動文案、EDM 草稿與資料摘要。
gpt-5.4-mini 點數倍率較低,適合想控制成本,同時保留一定輸出品質的工作流。
適合任務:
- 社群貼文草稿、EDM 草稿、活動文案
- 客服回覆、社群留言回覆、私訊回覆建議
- 報表摘要、文章重點整理、市場資訊彙整
- 需要穩定文字品質的一般行銷自動化任務
- 頻率較高、需要控制點數成本的工作流
使用建議:
如果任務需要一定品質,但不需要深度策略推理,可以從這一層開始測試,若輸出品質已符合需求,就能作為日常工作流的主要模型選擇;若遇到重要提案、複雜分析或高風險對外溝通,再升級到專家推理級模型。
🟡 進階標準型
gpt-4.1(2.6 倍)
這一層適合需要閱讀大量文字、整理長篇資料,或對輸出格式有明確要求的任務。相較一般內容產出,gpt-4.1 更適合用在資料量較大、段落較長、需要維持上下文一致性的工作流。
例如:當行銷團隊需要整理產品手冊、活動簡報、客戶訪談紀錄、研究報告或品牌素材時,可以使用這類模型協助摘要重點、萃取資訊,並依照指定格式輸出。
適合任務:
- 長篇文件摘要,例如產品手冊、活動報告、白皮書、客戶訪談紀錄
- 知識庫內容整理,例如 FAQ、產品規格、品牌語氣指南
- 指定格式輸出,例如表格、條列重點、欄位化資料整理
- 多段文字比對,例如不同版本文案、競品資訊或客戶需求整理
- 需要保持上下文一致的文章改寫與資料彙整
使用建議:
如果任務重點在於讀懂長資料、整理結構、維持輸出格式穩定,可以考慮使用 gpt-4.1。若任務只是短文改寫、簡單摘要或大量分類,可以先用較低倍率模型測試,降低點數消耗。
🟢 高效輕量/高性價比/極速微型
gpt-5.4-nano(0.55 倍)/gpt-5-mini、gpt-4.1-mini(0.3 倍)/gpt-5-nano(0.1 倍)
這一層適合大量、固定、低風險的行銷自動化任務,尤其是輸入與輸出規則明確、判斷難度較低的流程,相較高階模型,輕量模型的點數消耗較低,適合用在需要頻繁執行或大量批次處理的場景。
其中,gpt-5-nano 是 GPT 系列中點數消耗最低的選擇,適合簡單分類、標籤整理與初步摘要。
gpt-5-mini/gpt-4.1-mini 適合在成本與品質之間取得基礎平衡。
gpt-5.4-nano 則可用於希望維持較好輸出品質,同時控制點數消耗的輕量任務。
適合任務:
- 大量留言分類、標籤整理、情緒初判
- IG 留言、Google 商家評論、Threads 留言回覆草稿
- 關鍵字整理、短文摘要、資料初篩
- 固定格式改寫,例如標題改寫、CTA 改寫、短句潤飾
- 低成本、高頻率的自動化流程
- 規則明確、推理需求較低的讀取與輸出任務
使用建議:
如果任務量大、格式固定、輸出風險低,可以先從這一層模型開始測試,若輸出品質不足,再升級到進階旗艦級或高階模型,這樣能讓 AI Agent 在大量日常任務中維持較好的點數使用效率。
Google Gemini 系列怎麼選
Gemini 系列適合需要處理大量資訊、圖文內容與多來源資料的工作流。對行銷團隊來說,如果任務包含圖片、商品素材、社群截圖、活動頁面、簡報內容,或需要一次整理多份資料,Gemini 會是值得測試的模型選項。
🔴 旗艦效能級
Gemini 3.1 Pro(2.9 倍)
Gemini 3.1 Pro 適合用在需要深入理解、跨資料整合與策略判斷的任務。當工作流同時涉及文字、圖片、文件或多份資料時,可以使用這一層模型協助整理資訊、找出重點,並產出較完整的分析結果。
對行銷人來說,Gemini 3.1 Pro 很適合放在市場研究、競品分析、素材判讀或多文件整合的節點。例如,整理競品活動頁、分析社群素材方向、閱讀多份報告後彙整成行銷建議。
適合任務:
- 市場研究、競品策略整理、活動檔期分析
- 商品頁、活動頁、社群截圖等圖文內容分析
- 多份簡報、報告、文章或網頁內容整合
- 廣告素材、社群素材、視覺溝通方向判讀
- 需要結合多來源資訊的行銷建議與內容規劃
使用建議:
如果任務包含多份資料、圖文內容或較複雜的分析需求,可以優先測試 Gemini 3.1 Pro,若任務只是簡單摘要、分類或短文整理,可以先使用 Flash 或 Flash-Lite 類型模型,以降低點數消耗。
🟢 推薦極致旗艦
Gemini 3 Flash(0.75 倍)/Gemini 3.1 Flash-Lite(0.35 倍)
這一層適合需要快速處理、頻繁執行,且希望控制點數成本的行銷工作流。相較 Pro 等級模型,Flash 與 Flash-Lite 更適合放在高頻任務中,例如社群內容草稿、即時回覆建議、圖片素材初步判讀與大量資料整理。
其中,Gemini 3 Flash 適合需要速度與品質兼顧的日常任務,例如社群貼文產出、活動文案整理、廣告素材分析與報表摘要。
Gemini 3.1 Flash-Lite 點數倍率更低,適合大量生產、批次處理或固定格式任務。
適合任務:
- 社群貼文、短文案、留言回覆草稿
- 客服對話、私訊回覆、FAQ 初步回覆建議
- 產品圖片、廣告素材、社群截圖的初步分析
- 活動資訊、新聞內容、報表重點的快速摘要
- 大量資料整理、分類、標籤與初步判讀
- 需要快速回應、推理需求較低的行銷工作流
使用建議:
如果任務需要高頻率執行,例如每日社群監測、留言回覆、素材初步分析或大量摘要,可以先從 Gemini 3 Flash 或 Gemini 3.1 Flash-Lite 開始測試。若任務涉及較複雜的策略判斷、多資料整合或重要對外內容,再升級到 Gemini Pro 等級模型。
🟡 進階標準型
Gemini 2.5 Pro(2.3 倍)
Gemini 2.5 Pro 適合需要處理長篇資料、多份文件與複雜內容整理的任務。它支援較長上下文,適合一次閱讀大量文字資料,並協助整理重點、歸納脈絡與產出報告。
對行銷團隊來說,這一層適合用在需要「看很多資料後再整理結論」的工作流,例如市場研究、新聞資料彙整、活動成效報告、競品資料彙整、客戶訪談紀錄整理,或多份文章、簡報、報表的重點摘要。
適合任務:
- 長篇文件摘要,例如報告、簡報、白皮書、客戶訪談紀錄
- 多份資料彙整,例如市場資訊、競品內容、新聞資料整理
- 活動成效報告、月報、專案回顧內容生成
- 需要跨段落理解與脈絡整理的行銷分析
- 多步驟資料整理與報告初稿產出
使用建議:
如果任務包含大量文字資料,或需要一次整理多份文件,可以優先測試 Gemini 2.5 Pro。若任務只是短文摘要、簡單分類或固定格式整理,則可以先使用 Gemini Flash 或 Flash-Lite 類型模型。
🟢 輕量/省錢
Gemini 2.5 Flash(0.6 倍)/Gemini 2.5 Flash-Lite(0.2 倍)
這一層適合大量、重複性高、規則明確的行銷自動化任務。Flash 系列點數消耗較低、處理速度快,適合用在需要批次執行的工作流中。
其中,Gemini 2.5 Flash 適合需要兼顧速度與基本品質的日常任務,例如大量摘要、內容分類、簡短文案整理。
Gemini 2.5 Flash-Lite 是 Gemini 系列中點數倍率最低的選擇,適合用在資料初篩、簡單分類與固定格式輸出。
適合任務:
- 大量留言、評論、私訊的批次分類
- 關鍵字整理、標籤建立、資料初步分群
- 簡短內容翻譯、摘要、改寫
- 社群貼文或商品文案的初稿產出
- 固定格式輸出,例如表格整理、欄位萃取
- 高頻率、低複雜度的自動化流程
使用建議:
如果任務量大、格式固定、判斷難度不高,可以先從 Gemini 2.5 Flash-Lite 開始測試;若需要稍微提高文字品質或內容理解能力,再升級到 Gemini 2.5 Flash。這一層很適合作為每日監測、批次整理與大量初步處理的起點。
Anthropic Claude 系列怎麼選
Claude 系列適合重視文字表達、語氣一致性與格式穩定的行銷任務。對需要長文撰寫、品牌溝通、內容潤飾、簡報敘事或複雜文字整理的工作流來說,Claude 是值得測試的模型選項。
🔴 專家推理級
Claude Opus 4.6、Claude Opus 4.5(7.3 倍)
Opus 是 Claude 系列中較高階的模型層級,適合處理需要深度理解、複雜判斷與高品質文字輸出的任務。當工作流涉及品牌策略、長篇內容、重要提案或高風險對外溝通時,可以考慮使用 Opus 等級模型。
其中,Claude Opus 4.6 可優先用於需要較高輸出品質與更完整推理的任務。
Claude Opus 4.5 則適合已建立穩定使用流程、需要維持一致輸出品質的工作流。
兩者點數倍率皆為 7.3 倍,建議放在高價值、低頻率的任務節點。
適合任務:
- 品牌策略文案、品牌觀點文、長篇行銷文章
- 重要客戶提案、主管簡報、合作簡報內容
- 複雜產品價值轉譯,例如把技術功能整理成商業溝通語言
- 品牌危機應對、正式聲明、對外溝通草稿
- 多步驟 AI Agent 工作流中的高階判斷與內容潤飾
- 對語氣、架構、邏輯與輸出完整度要求較高的任務
使用建議:
Opus 等級模型適合用在品牌溝通與高品質內容輸出的後段,例如策略整理、文章精修、提案優化或對外聲明檢查。若任務只是大量摘要、留言分類或簡短回覆,可以先使用較低倍率模型完成前置處理,再將整理後的內容交給 Opus 進行深度潤飾與判斷。
🟠 旗艦效能級
Claude Sonnet 4.5(3.7 倍)
Sonnet 4.5 適合多數需要穩定文字品質、清楚結構與良好語氣控制的行銷任務,相較 Opus 等級模型,Sonnet 點數倍率較低,也更適合放在日常工作流中,處理內容產出、客戶溝通、資料整理與多輪互動任務。
對行銷團隊來說,Sonnet 4.5 可以用在社群內容、A/B 測試文案、客服回覆建議、品牌語氣調整等情境。若工作流需要維持文字自然度、輸出格式一致性,或需要多輪對話式互動,Sonnet 會是很值得測試的選項。
適合任務:
- 社群貼文、EDM、A/B 測試文案生成
- 客服對話 Agent、品牌回覆自動化
- 產品介紹、活動文案、銷售溝通內容
- 多輪互動式任務,例如私訊回覆、客戶問答、內容修正
- 需要語氣一致、格式穩定的一般行銷自動化流程
使用建議:
如果任務需要一定品質與語氣控制,但還不到重要提案或高風險對外溝通的層級,可以先測試 Sonnet 4.5。它適合成為日常行銷工作流中的高品質輸出模型;若任務複雜度更高,再升級到 Opus 等級模型。
🟢 高效輕量級
Claude Haiku 4.5(1.25 倍)
Haiku 4.5 適合速度要求高、任務規則明確、點數成本需要控制的工作流。它保留 Claude 系列在語氣與格式上的穩定特性,適合用在不需要深度推理,但仍希望輸出自然、清楚、有一致風格的任務。
對行銷團隊來說,Haiku 4.5 很適合處理簡短回覆、內容分類、標籤整理、初步摘要與大量批次任務。若任務需要高頻率執行,又希望比一般輕量模型有更穩定的文字表現,可以從 Haiku 開始測試。
適合任務:
- 簡短客服問答、社群留言回覆草稿
- 內容分類、標籤整理、情緒初判
- 短文摘要、重點萃取、固定格式整理
- 品牌語氣一致的簡短文案改寫
- 高頻率、大量呼叫、需要控制點數成本的自動化流程
使用建議:
如果任務偏向快速回覆、批次整理或簡短內容生成,可以先使用 Haiku 4.5,若需要長篇內容、策略判斷或更完整的品牌敘事,再升級到 Sonnet 或 Opus 等級模型。
如果還是不知道怎麼選?先記這張圖
看到 ChatGPT、Gemini、Claude 這麼多模型,一開始覺得眼花很正常,對行銷人來說,最快的理解方式是先不要從模型名稱開始看,先從任務本身判斷。
選擇邏輯其實就一條線:任務越複雜、越重要,就往上選;任務越單純、量越大,就往下選。
實際決策只需三步:
第一步:先問「這個任務如果 AI 答錯,代價大不大?」代價大 → 往上選。
第二步:用中間層跑一次,覺得夠好 → 試試下面那層省點數;覺得不夠好 → 換上面那層。
第三步:同一個任務,換個品牌跑跑看,GPT、Gemini、Claude 各有手感,找到你順眼的那個就固定用。

圖二、AI Agent 模型選擇:依任務複雜度與點數成本,快速判斷不同模型適合的使用情境
沒有最好的模型,只有最適合當下任務的模型。
如果還是不確定該怎麼選,可以先從 Claude Sonnet 4.5 或 Gemini 3 Flash 開始測試,Claude Sonnet 4.5 適合需要語氣一致、格式穩定與多輪互動的任務,例如客服回覆、品牌文案、內容潤飾與提案整理;Gemini 3 Flash 則適合需要快速處理、批次整理與多模態分析的工作流,例如社群摘要、資料分類、報表重點整理、素材判讀與日常內容產出。
對多數行銷團隊來說,這兩個模型可以作為日常 AI Agent 工作流的起點,先用它們完成大部分常見任務,再依照任務複雜度、輸出品質與點數成本,逐步升級到更高階模型,或降級到更省點數的輕量模型。
👉 立即預約了解 Instag AI Agent !歡迎與我們聯繫,一起探索更多可能性!點我預約了解